专业的IT培训机构|腾科IT教育集团



大数据应用开发主要流程
发布时间: 2023-02-13
大数据应用的开发通常分为五个步骤:获取、存储、处理、访问和编译。获取指的是获取辅助数据,例如来自CRM或生产数据(ODS)的数据,并将其加载到分布式系统(例如Hadoop)中,为下一阶段的处理做准备。存储是指关于分布式文件系统(GFS)或分布式NoSQL存储系统、数据格式)、压缩和数据模型的决策。处理是指将收集的原始数据导入大数据管理系统,并将其转化为可用于分析和查询的数据集。分析是指对处理过的数据集应用各种分析查询,以获得所需的答案和见解。编译是指对进行收集、处理和分析的各种过程进行自动规划和协调,下图说明了开发大数据应用的过程:
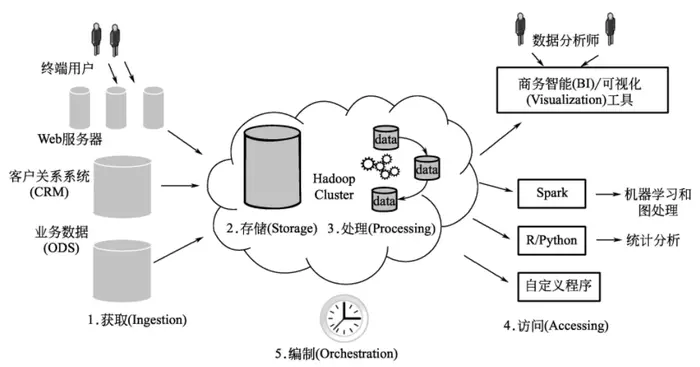
点击流分析被用来解释大数据应用开发过程中的各个步骤是如何实现的。在点击流分析的例子中,一个分布式文件系统(GFS)被用来存储数据,站点的日志文件和其他附加数据通过Flume检索并导入分布式系统。同时,Spark被用来处理数据。通过与商业智能工具的连接,分布式系统交互式地进行数据处理查询,并利用工具将操作过程组合成一个工作流程。
(1)大数据获取
有多种获取数据并导入至大数据管理系统的方法:
①文件传输∶此方法适合一次性传输文件,对于本任务面临可靠的大规模点击流数据获取,将不适用。
②Sqoop∶ Sqoop 是Hadoop 生态系统提供的将关系型数据管理系统等外部数据导入大数据管理系统的工具。
③Kafka∶ Kafka的架构用于将大规模的日志文件可靠地从网络服务器传输到分布式系统中。
④Flume∶Flume工具和Kafka类似,也能可靠地将大量数据(如日志文件)传输至分布式系统中。Kafka和Flume都适用于获取日志数据,都可以提供可靠的、可扩展的日志数据获取。
(2)大数据存储
在数据处理的每个步骤中,包括初始数据、数据变换的中间结果及最终的数据集都需要存储。由于每一个数据处理步骤的数据集都有不同的目的,选择数据存储的时候要确保数据的形式及模型和数据相匹配。
原始数据的存储是将文本格式的数据存储到分布式系统中。分布式系统具有以下一些优点:
①在序列数据处理过程中,需要通过多条记录来进行批处理转换;
②分布式系统可以高效率地通过批处理,处理大规模数据。
(3)大数据处理
使用Flume获取点击流数据,网络服务器上的原始数据在分析前需要进行清洗。例如,需要移除无效和空缺的日志数据、需要删除这些重复数据。清洗完数据后,还要将数据进行统一ID编号,在处理数据前需要对点击数据做进一步的处理和分析,包括对数据以每天或每小时为单位进行汇总,这能更快地进行之后的查询操作。事实上,对数据进行预处理是为了之后能高效地进行查询操作。大数据处理需要经历以下四步:
①数据清洗清理原始数据。
②数据抽取∶从原始点击数据流中提取出需要的数据。
③数据转换∶对提取后的数据进行转换,以便之后产生处理后的数据集。
④数据存储∶存储在分布式文件系统中的数据支持高性能查询方式。
(4)大数据分析
数据经过获取和处理后,将通过分析数据来获得想要了解的知识及答案。商业分析师通过以下几个工具来探索和分析数据:
①可视化(visualization)和商业智能工具(BI),例如Tableau和MicroStrategy.
②统计分析工具,例如R或Python。
③基于机器学习的高级分析,例如Mahout和Spark MLlib。
④SQL。
(5)大数据编制
数据分析经常临时性的需要,需要进行自动化编制。编制点击流分析的步骤如下:
首先,在获取数据阶段,通过Flume将数据连续传输到分布式系统中。
其次, 在数据处理阶段, 因为在一天结束时终止所有连接是常见的, 故采用每天执行会话算法。在开始处理工作数据流前,验证Flume写入分布式系统的当天数据。这种同步验证方式是常见的,因为通过简单地查看当前日期分区的情况,可以校验当前日期数据是否开始写入大数据管理系统。
上一篇: java类构造方法特点
下一篇: 什么是自然语言处理

全国统一咨询热线:18924184114
广州总校区:广州市天河区科韵路棠安路188号乐天大厦2楼整层
深圳分校区:深圳市南山区南油第四工业区2栋601-603室








